


It has been a while, again, my friends. I’ve been tirelessly typing away code blocks in Jupyter Notebooks and Visual Studio Code while keeping API documentation open on my other window. I dove into a project dealing with neural networks for image classification only knowing basic Python, and perhaps the most basic functions Pandas and Numpy have to offer.
Although I’d like to write this blog post in-depth, I don’t want this to trigger any plagiarism-finding technologies, so this is going to cover the learning/personal aspects of the capstone more than the technical portions.
The Project
Did I have to do image classification for my capstone project? Probably not. I considered doing something with a neat coffee bean CSV that I found (that I no longer remember the source), but I couldn’t easily figure out what business problem to solve with it. Maybe I’ll get back to that dataset one day.
The computer science capstone at WGU only requires you to apply machine learning or artificial intelligence to a business problem, so it could deal with predicting something using structured data (like financial, medical, or weather data) or something less structured (like images and audio). There are so many choices to pick from, and if you collect your own data I reckon it would open up even more choices.
At first, though, I did not want to collect my own data, even though my original plan was to collect sales data from my work to try to forecast demand for baked goods, but I thought that it would take too long. Again, maybe that could be an idea for a future project. That was something that I really wanted to do but I think I’d spend more time collecting and cleaning data than creating an AI solution that can forecast demand.
So, after about three days of browsing Kaggle and scrolling through pages and pages of datasets, hoping that the title of one would spark an idea in my mind, I stumbled upon this one, titled “Wild Edible Plants”.
“Hey Leanna, weren’t you really interested in herbalism and foraging a few years back? How about you merge those two interests together?”
So I did. I really did try.
Except I ended up not using that dataset. In retrospect, it might’ve been because I had no idea what I was doing when I was trying out MobileNetV2, Xception, and NASNetMobile as potential models to use for transfer learning; the accuracy was very low, so I forewent that and, upon seeing that one other WGU CS student gathered their own images of creepy-crawlies for image classification in the Capstone Excellence archive, I was inspired to do the same.
My topic switched to invasive plant species in the state of Virginia, in which a good overview of the topic is found on Virginia’s Department of Forestry website here.
Some Pre-studying…
Through WGU, I had access to Artificial Intelligence – A Modern Approach (Russel and Norvig), so I read chapter 27, which was about computer vision. I will likely go through the book again and read it from the beginning.

A couple months ago, I tried to read Chapter 22, section 3, which was about convolutional networks, but I could not comprehend what it was saying. Tensors? Kernels? ReLU? What are those?
After completing the capstone, I’ve gotten a little more familiar.
There were also a few other resources that I used which I listed in my previous post. Those helped me better understand what I was working with.
Data Collecting
This had to be the first time I accessed an API for a website. I chose iNaturalist for sourcing photos since you can look for ones licensed under the Creative Commons. Their API can be found here. I only used the GET /observations operation as that’s all I needed; I wanted to fetch some attribution information, the species name, and the image URL for the photos.
One thing I’m going to indirectly mention throughout this entire post is that this project taught me to read carefully. I’m a person who likes to dive in head first, but I spend a lot more time after trying to figure out why something isn’t working. And what do I see in the API documentation? The solution!
To be fair, though, this stage was not that hard to do. The Requests library helped me pass in some parameters for my search. The entire thing was one massive for-loop. I needed at least 10,000 photos of each plant species. Looking back, I may have not needed to sprinkle so many sleep() lines in my code, but I decided that I should be nice and not bog down iNaturalist’s servers. It wouldn’t have taken 5-7 hours to download all of the metadata and images that I needed if I hadn’t put any sleep() in.
They were all placed nicely into little folders of their own. If I could, I would’ve uploaded the dataset with my capstone submission, but WGU has a 500MB limit for that. My dataset was around 12GB.
Data Cleaning(?)
I got about 15,000 to 16,000 images per species, except for one, which I reran my downloading script for more. The more the merrier, right? It was well over the 10,000 per species that I needed, but I figured the more photos that the model could be trained on, the better. I just rounded it to 15,000 since that wouldn’t be too much work on my end to delete the excess photos. Anything that just did not look good was deleted: the picture was too far from the subject; people or text/watermarks; blurry; all that fun stuff. This part was what I wish could be automated, but I don’t think we’re there yet.
Training the Model
If I told you this took 24 days to figure out, would you believe me?
This was when I was using the Kaggle dataset I mentioned earlier. I believed that since the dataset didn’t have enough photos, the model didn’t attain a high enough accuracy. I would need to test it again with my current model setup (which was simply done by, again, reading the docs—this one would be the “Transfer learning & fine-tuning” article on Keras’ API docs).
For Xception especially, since it expected an input between -1 and 1 for the pixels, I was absolutely astonished when I saw my validation accuracy for that go from 42% to 99% by adding in an input layer, Rescaling layer, and changing my Sequential model into a Functional one, which only took a few minutes more to do. I was just confused afterward because the other convolutional neural network capstones and most of the tutorials I did used the Sequential model.
- I was mainly confused at the sight of this:
x = layers.Dense(64, activation="relu")(x)
- “Why is that (x) just sitting there at the end?! This is confusing!” Yes, it is more confusing, but it makes sense, somehow…
Again—read the docs!
I did not use Xception for my final product, however. Xception was the most accurate, but the resulting weights file was five times as big as the second most accurate, MobileNetV2, which was not even half a percent less.
Making the App
Honestly, it was a bit more anti-climatic than I thought. I was ready to do something that I thought would be the coolest and hardest thing I’ve ever done, but it was honestly… not that hard at all.
I used the Streamlit framework to build the app and deployed it on a Hugging Face Space with a Docker container. All I had to do was load the model and then use a few Streamlit widgets here and there to allow the user to upload their own image and let the model attempt to classify what’s in it, and then spit out the result.
While I’m all fine with using a more command line-style interface, I had the notion that most people are not, so I tried my best to create a web app that had a GUI for someone to use.
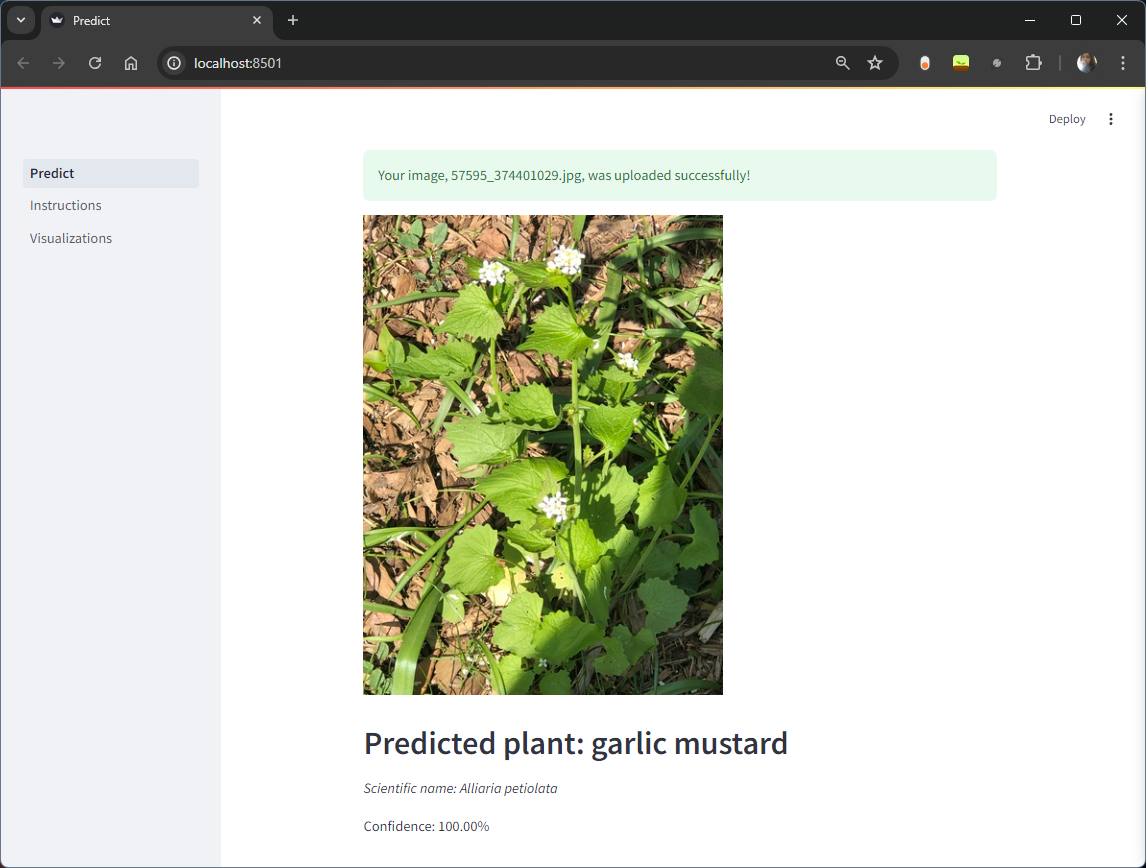
Streamlit did the heavy lifting with the design, and for the sake of this project, I’m glad it did. Having to collect data, clean data, make a model, train the model, make an app, and then deploy it? That’s a lot of work! Making it pretty would take longer… and I love making things look nice.
I almost tried implementing this idea with Django, and honestly, I’m glad I didn’t for this prototype. I took the short Django course on Codecademy but I didn’t feel like it sufficiently prepared me for implementing a machine learning project with it, so when I learned that Streamlit exists, I immediately switched to that.
Takeaways
Some important lessons I learned.
- Read the docs.
- Read the docs again.
- Maybe… read the docs more?
People have already done this before. You might just have a new way of implementing it. Learn from their struggles, and then learn from your mistakes. I think that’s a better use of time.
Me, though? I think I will keep on making my own mistakes first because even though I try to keep everyone else’s warnings well, if I personally have not experienced it, it’s harder for me to understand the implications of it.
It’s the same with writing stories: if I’ve never experienced what a character goes through, I can’t write it as well.
So try many things. It adds to your knowledge bank 😉
After completing this project, however, I’d like to try out more AI/ML projects and deploy a solution with them. Making a model is half the challenge; making it easily usable for everyone is the other half.
What to do Now?
Earlier today (July 22, 2024), between 11 am and noon, I got a notification saying that my capstone task had passed. Upon seeing that, I hopped out of my chair and hopped around my room in glee. After 21 months of studying (16 of which were spent as an active WGU student), I completed my degree. Graduation paperwork still needs to be processed, but it’s effectively done.
My resume needs an update and I need to keep applying for new jobs. I’ll probably move around the sections of my resume, bringing projects to the top of it to focus on those skills, and then do more projects.
I’m going to try really hard to work on “personal branding”. It was easy when I went by “Percy” on in ArcheAge and on my associated game blog, but me? An identity that changes so frequently is hard to capture. If anything, my branding would be entropic.

As you learn more, and apply those learnings to your life, your life changes.
As your life changes, you change in response, and the other way around applies, where you change and life changes in response.
They are interconnected; to have a stable, myopic identity would mean that no changes are occurring.
I believe my identity would not be something so narrow; something like “learner” would be the best fit. Such a role transcends the limits of identity; one day you may be a student of one science, and the next day, a student of a form of art. Broadness. Generalizing.
Changing TAKES TIME, though. We must be patient. It might take several iterations, studying in many different ways, condensing knowledge to then expand upon it, looping over and over.
More practically said, to make the most of my Codecademy subscription, I’m likely going to take advantage of their coding challenges to get my brain working in “brain teaser” mode, and go back to finishing their Data Scientist – ML Specialization career path.
What do I want to do in my career? That’s a difficult question to answer. If I haven’t tried everything yet, how will I know what I want to do?
Outside of career-related stuff, I want to follow Teach Yourself Computer Science‘s suggestions of resources to look over to get a more well-rounded view of the CS landscape. Of course, technologies change, but having the foundation would be useful. I can always leverage the knowledge there and apply it to any articles that I read.
Speaking of which…
Some Research Papers I Looked At

I wanted to also share the papers that I looked at for inspiration on what exactly to do. There are lots of people who did some work on classifying plant images, and from what I’ve seen a number of them were about classifying diseases given a picture of a leaf.
Note: I don’t think every paper below deals with plant image classification, but all of them should relate to convnets. I only skimmed them briefly.
- Batchuluun, G., Nam, S. H., & Park, K. R. (2022). Deep Learning-Based Plant-Image classification using a small training dataset. Mathematics, 10(17), 3091. https://doi.org/10.3390/math10173091
- Ibarra-Pérez, T., Jaramillo-Martínez, R., Correa-Aguado, H. C., Ndjatchi, C., Del Rosario Martínez-Blanco, M., Guerrero-Osuna, H. A., Mirelez-Delgado, F. D., Casas-Flores, J. I., Reveles-Martínez, R., & Hernández-González, U. A. (2024). A performance comparison of CNN models for bean phenology classification using transfer learning techniques. AgriEngineering, 6(1), 841–857. https://doi.org/10.3390/agriengineering6010048
- Irmak, G., & Saygili, A. (2023). A novel approach for tomato leaf disease classification with deep convolutional neural networks. Tarım Bilimleri Dergisi/Ankara ÜNiversitesi Ziraat FaküLtesi Tarım Bilimleri Dergisi. https://doi.org/10.15832/ankutbd.1332675
- Lanjewar, M. G., & Panchbhai, K. G. (2022). Convolutional neural network based tea leaf disease prediction system on smart phone using paas cloud. Neural Computing & Applications, 35(3), 2755–2771. https://doi.org/10.1007/s00521-022-07743-y
- Lanjewar, M. G., Shaikh, A. Y., & Parab, J. (2022). Cloud-based COVID-19 disease prediction system from X-Ray images using convolutional neural network on smartphone. Multimedia Tools and Applications, 82(19), 29883–29912. https://doi.org/10.1007/s11042-022-14232-w
- Liu, J., Zhang, K., Wu, S., Shi, H., Zhao, Y., Sun, Y., Zhuang, H., & Fu, E. (2022). An Investigation of a Multidimensional CNN Combined with an Attention Mechanism Model to Resolve Small-Sample Problems in Hyperspectral Image Classification. Remote Sensing, 14(3), 785. https://doi.org/10.3390/rs14030785
- Lobaton, E. a. P. G. O. (2024). LEAFLET: a Web-Based Leaf classification system using convolutional neural networks. Journal of Electrical Systems, 20(1), 18–32. https://doi.org/10.52783/jes.657
- Pattnaik, G., Shrivastava, V. K., & Parvathi, K. (2020). Transfer Learning-Based Framework for Classification of pest in tomato plants. Applied Artificial Intelligence, 34(13), 981–993. https://doi.org/10.1080/08839514.2020.1792034
- Taslim, A., Saon, S., Mahamad, A. K., Muladi, M., & Hidayat, W. N. (2021). Plant leaf identification system using convolutional neural network. Bulletin of Electrical Engineering and Informatics, 10(6), 3341–3352. https://doi.org/10.11591/eei.v10i6.2332
- Turkoglu, M., Aslan, M., Arı, A., Alçin, Z. M., & Hanbay, D. (2021). A multi-division convolutional neural network-based plant identification system. PeerJ. Computer Science, 7, e572. https://doi.org/10.7717/peerj-cs.572
- Yulita, I. N., Rambe, M. F. R., Sholahuddin, A., & Prabuwono, A. S. (2023). A convolutional neural network algorithm for pest detection using GoogleNet. AgriEngineering, 5(4), 2366–2380. https://doi.org/10.3390/agriengineering5040145
- Zefri, W. M. a. H. B. W., & Nordin, S. (2022). Plant recognition system using convolutional neural network. IOP Conference Series. Earth and Environmental Science, 1019(1), 012031. https://doi.org/10.1088/1755-1315/1019/1/012031
- Zin, I. a. M., Ibrahim, Z., Isa, D., Aliman, S., Sabri, N., & Mangshor, N. N. A. (2020). Herbal plant recognition using deep convolutional neural network. Bulletin of Electrical Engineering and Informatics, 9(5), 2198–2205. https://doi.org/10.11591/eei.v9i5.2250
Cover photo by Google DeepMind on Pexels.com












